誤差関数と実効学習率
ゼロから作るDeep Learning 5 を読むのに勉強したことのメモ
Step 6
簡単なニューラルネットワークと勾配計算について説明されている章でした。 もはや本文とは関係ない領域ですが、Bishop先生の Deep Learning 7章 をまとめるいい機会なので、学習率 $\eta$ による収束の挙動の違いについて書きます。
参考:学生の時に作った資料(DL, Chapter 7)
誤差関数の収束
最小値近傍の局所2次近似
最小値付近の点 \(\mathbf{w}^*\) の近くでのテイラー展開を考えれば、誤差関数をヘッセ行列 \(\mathbf{H}\)を用いて近似することができ、
\[E(\mathbf{w}) \approx E(\mathbf{w}^*) - \nabla E(\mathbf{w}^*)^{\mathrm T}(\mathbf{w}-\mathbf{w}^*) - \frac{1}{2}(\mathbf{w}-\mathbf{w}^*)^{\mathrm T}\mathbf{H}(\mathbf{w} - \mathbf{w}^*)\]最小値まわりでは1階微分は0なので、
\[E(\mathbf{w}) \approx E(\mathbf{w}^*) + \frac{1}{2}(\mathbf{w}-\mathbf{w}^*)^{\mathrm{T}}\mathbf{H}(\mathbf{w}-\mathbf{w}^*) \tag{1}\]このヘッセ行列から、局所的な形(曲率)が分かることをみていく。
固有値・固有ベクトルで座標変換
\(\mathbf{H}\) の固有値問題
\[\mathbf{H}\mathbf{u}_i = \lambda_i \mathbf{u}_i\]を考える。 最小値からのずれを固有ベクトル基底で展開し、\(\mathbf{w}\) が \(\mathbf{u}_i\) 方向にどれだけ最小値から離れているかを表す量として \(\alpha_i\) を定義すれば、
\[\mathbf{w}-\mathbf{w}^* = \sum_i \alpha_i \mathbf{u}_i \tag{2}\]式 (1) を \(\mathbf{w}\) で微分すれば、2次近似の下での勾配は以下で表される。
\[\nabla E(\mathbf{w}) = \mathbf{H}(\mathbf{w}-\mathbf{w}^*) = \sum_i \lambda_i \alpha_i \mathbf{u}_i \tag{3}\]これは、方向 \(\mathbf{u}_i\)の勾配成分は \(\lambda_i \alpha_i\) であり、曲率 \(\lambda_i\)が大きい方向ほど、同じ距離 \(\alpha_i\) でも勾配が大きいということを示している。
重み更新の式は式 (2) から同じ基底で以下のように書くことができ、ベクトル更新を各固有ベクトル軸に分解可能であることがわかる。
\[\Delta\mathbf{w}=\sum_i \Delta\alpha_i \mathbf{u}_i \tag{4}\]以上のことから、\(\alpha_i\) は、固有ベクトル \(\mathbf{u}_i\) 方向のスカラであるから、\((\mathbf{w}-\mathbf{w}^*)\) について固有ベクトル方向の射影を計算することで、以下のように書ける。
\[\mathbf{u}_i^{\mathrm{T}}(\mathbf{w}-\mathbf{w}^*)=\alpha_i\]勾配降下法
単純な勾配降下法は、以下のように書ける。
\[\mathbf{w}^{(\tau)}=\mathbf{w}^{(\tau-1)}-\eta \nabla E(\mathbf{w}^{(\tau-1)})\]これを、式 (3), (4) で計算した固有ベクトル方向に関する分解の式と組み合わせると、各方向ごとに以下が得られる。
\[\Delta\alpha_i = -\eta \lambda_i \alpha_i\]よって、最小値からのズレ \(\alpha\) の更新式は以下 \(\alpha_i^{\mathrm{new}}=\alpha_i^{\mathrm{old}}+\Delta\alpha_i = (1-\eta\lambda_i)\alpha_i^{\mathrm{old}} \tag{5}\)
収束条件
式 (5) の更新式から、\(\alpha_i\)の収束条件(発散を避ける条件)は以下であることが分かる。
\[|1-\eta\lambda_i|<1 \tag{6}\]\(T\) ステップ後は
\[\alpha_i(T) = (1-\eta\lambda_i)^T\alpha_i(0)\]なので、\(T\to\infty\)で \(\alpha_i = \mathbf{w} - \mathbf{w}^* \to 0\) \(\mathbf{w}\to\mathbf{w}^*\)
式 (6) の条件から、以下の不等式が得られる。
\[-1 < 1-\eta\lambda_i < 1 \Longleftrightarrow 0 < \eta\lambda_i < 2 \Longleftrightarrow \eta < \frac{2}{\lambda_i}\]最小値近傍(局所最小)では通常 \(\lambda_i>0\) なので、全方向で同時に成り立たせるには最大の固有値 \(\lambda_{\max}\) を使って、
\[\eta < \frac{2}{\lambda_{\max}}\]と制限すればよいことが分かる。
収束速度
\(\eta\) をできるだけ大きく \(\eta=\frac{2}{\lambda_{\max}}\) にすると、各方向の減衰率は以下のようになる。
\[\alpha_i(T)=\Bigl(1-\frac{2\lambda_i}{\lambda_{\max}}\Bigr)^T\alpha_i(0)\]このとき、\(\alpha_i\) の更新幅が最も小さく(=遅く)なるのは、\(\lambda_i\) が最も小さい \(\lambda_{\min}\) の方向で、
\[\alpha(T)=\Bigl(1-\frac{2\lambda_{\min}}{\lambda_{\max}}\Bigr)^T\alpha(0)\]が収束の律速になる。固有値が小さい軸はパラメータ空間の最小値とのズレ \(\mathbf{w} - \mathbf{w}^*\) が最も更新されにくいことを表しており、つまりパラメータ空間の楕円における長い軸(勾配が小さい、平たい方向)に対応しており、\(\frac{2\lambda_{\min}}{\lambda_{\max}}\) から、最大の固有値と最小の固有値の差が大きいほど収束が遅いことが分かる。
[!Key point]
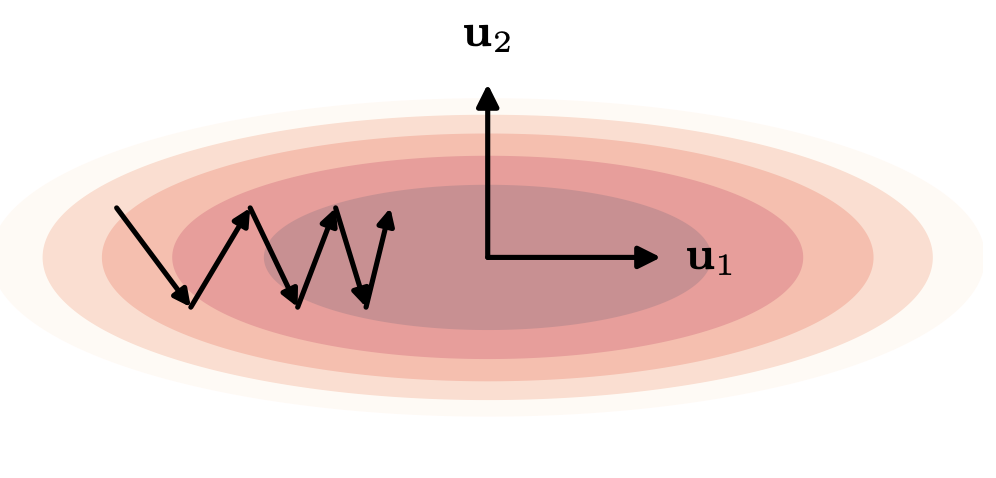
- Deep Learning 図7.3 参照
- \(\lambda_{\max}\)(勾配が急な方向)が \(\eta\) の上限を決める
- \(\lambda_{\min}\)(勾配が緩やかな方向)が 収束速度を決める
- 細長い谷(\(\lambda_{\min}/\lambda_{\max}\) が小さい)ほどGDの収束が遅くなる
Momentum
前節の通り、\(\lambda_{\max}\) と \(\lambda_{\min}\)が大きく異なる場合に収束が遅くなる。これに対処するために、重み空間の動きに慣性項を入れて振動を滑らかにする Momentum が提案された。
更新式
\[\Delta\mathbf{w}^{(\tau-1)} = -\eta\nabla E(\mathbf{w}^{(\tau-1)}) + \mu \Delta\mathbf{w}^{(\tau-2)} \tag{7}\]ここで、 \(\mu\) がMomentum パラメータ (\(0\le \mu \le 1\) ) であり、直前の更新幅 \(\Delta\mathbf{w}^{(\tau-2)}\) を次の更新に混ぜる慣性の役割を果たす。
実行学習率
1. 滑らかな斜面
曲率が小さく、常に一定の勾配になるような滑らかな斜面について考えると、どのタイムステップでも勾配が変わらない状況は以下のように書ける。
\[\nabla E(\mathbf{w}^{(\tau-1)})=\nabla E(\mathbf{w}^{(\tau-2)})=\cdots=\nabla E\]このとき、式 (7) の更新式を繰り返し代入すると、
\[\Delta\mathbf{w} = -\eta\nabla E,(1+\mu+\mu^2+\cdots)\]となり、\(\mid\mu\mid<1\)と等比級数の和より、パラメータの更新幅は以下のように書ける。
\[\Delta\mathbf{w} = -\frac{\eta}{1-\mu}\nabla E\]つまり、実効学習率が \(\eta \to \frac{\eta}{1-\mu}\) に増える。この事から、勾配の向きがずっと同じなら、過去の更新が同じ方向に積み上がって更新の速度が加速することが分かる。
2. 振動する領域
一方で、谷の壁のように曲率が大きい方向では、GDは左右に振動しやすい。極端な例ではあるが、振動によって勾配の符号が毎回反転する場合について考える。このとき、各タイムステップでの勾配は以下のようになる。
\[\nabla E(\mathbf{w}^{(\tau-1)})=-\nabla E(\mathbf{w}^{(\tau-2)})=\nabla E(\mathbf{w}^{(\tau-3)})=\cdots\]前節と同様に式 (7) の更新式を繰り返し適用すると、公比 \(-\mu\) の等比数列の和を考えて、
\[\Delta\mathbf{w} = -\eta\nabla E,(1-\mu+\mu^2-\mu^3+\cdots) = -\frac{\eta}{1+\mu}\nabla E\]となり、実効学習率は以下のようになる。
\[\frac{\eta}{1+\mu} < \eta\]つまり、勾配が反転する方向(=振動方向)では、慣性項によって勾配が相殺され、パラメータの更新幅が小さくなる。
Summary
- 収束条件:\(\mid1-\eta\lambda_i\mid<1\) を全方向で満たす必要があり、結果として \(\eta < \frac{2}{\lambda_{\max}}\) が必要。
- 収束の遅さの原因:収束の速度は最も遅い方向の更新幅 \(\frac{\lambda_{\min}}{\lambda_{\max}}\) に支配される。
- Momentum:一貫した勾配方向では実効学習率 \(\eta/(1-\mu)\) で加速し、毎回振動するような極端な方向では実効学習率 \(\eta/(1+\mu)\) で減速する。